Over Thanksgiving vacation I decided I wanted to see how various subreddits were connected and what their relative sizes were. Some projects seemed to tackle this goal, but I didn’t like the interface or how old their datasets were so I started to build my own. I began by building a scraper that would look at a specific subreddit, find the related subreddits section (for this I used PRAW), parse the section for the subreddit links, and build a map of the connections. The application would visit each subreddit referenced until all known subreddits were visited. The code for the crawler is here: https://github.com/cdated/reddit-crawler
Since crawling the entire site (with rate-limiting) took a couple of days I eventually updated the crawler to insert the additions into MongoDB. This ensured progress would not be lost if the application crashed or the internet connection was interrupted. Once the dataset was generated I wanted to make an interactive graph anyone could access on the internet. So first I needed a simple web server that would accept a few parameter; subreddit, graph depth, and nsfw. Without much trouble I got a flask server to return a static graph image using Python’s graphviz library. I had a little experience with Heroku so decided to put my current work up there.
Having a public interface to my project, I was emboldened to improve the usability and wanted to try out D3.js. From the D3.js homepage I found an interactive graph example that would suit my needs. After altering the graph data to match the D3.js format I was able to get what I wanted working in JavaScript. This opened a lot of options for me to make the nodes draggable, turn the nodes into links, change the size of the nodes to represent the subscriber counts, and dynamically color the nodes and links to make graph look more attractive.
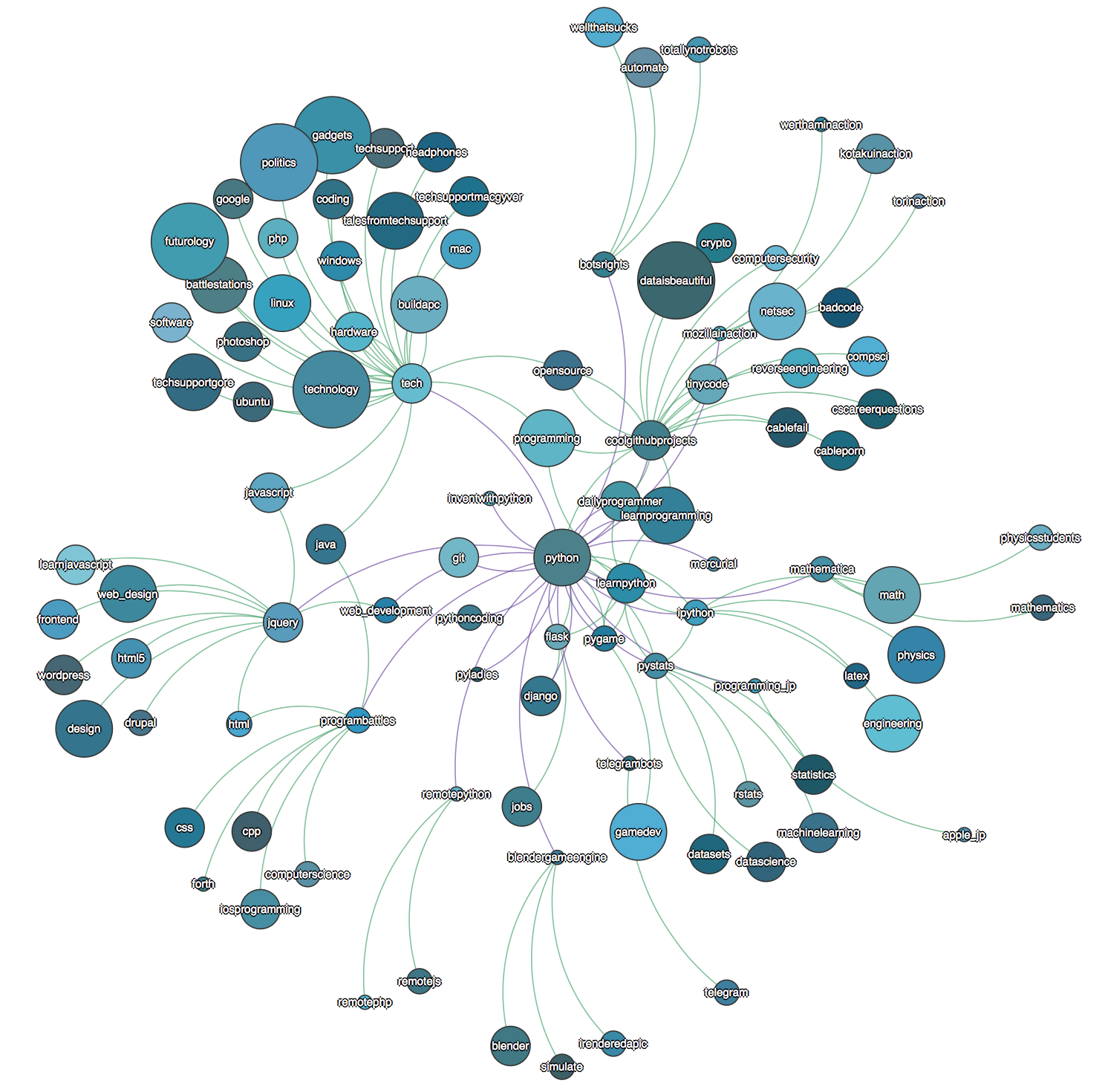
I still have a lot of changes I want to make to the project when I have time. The database currently uses MongoLab’s free tier which makes the deployment a lot slower than my development environment. I eventually want to update the crawler to use Postgresql’s hstore then I can leverage Heroku’s Posgresql support. Likewise, while deploying in Heroku is very convenient it also imposes many constraints. Migrating to a VPS would force me to work at all levels of the deployment.
The code: https://github.com/cdated/subredditor
Live instance: http://subredditor.com